
Ananda A.V. Francis
Khoury College of Computer Sciences
Northeastern University
Boston, MA 02115
Research Thesis
This investigation examines how different Deep Neural Network architectures balance predictive performance, model complexity, algorithmic fairness, and resource utilization in multilingual audio classification. An ongoing challenge for state-of-the-art language models is the disparity in performance between high-resource languages and low-resource languages. This divide reinforces historical patterns of marginalization when models perform better on Western languages over languages of the global majority. To address these challenges, we propose a novel Multi-Objective Evolutionary Algorithm that jointly conducts Neural Architecture Search and Hyperparameter Optimization, to produce a Pareto set of non-dominated models for classifying speech audio across 6 languages: Jamaican Patois, Ghanaian Pidgin, American English, European Spanish, Chinese Mandarin, and Indian Hindi. Additional filtering of the approximated Pareto front, using a validation set unseen in the neuroevolution process, proved a significant step in true Pareto front approximation (6.98% hypervolume increase). Neural architecture type and topology had a significant impact on performance across all 4 objectives. Linear models outperformed Recurrent Neural Networks (RNNs) due to RNNs suffering from exploding gradients at high rates. Globally, the models had the best discrimination power for Mandarin, followed by Spanish and the worst overall performance on Patois, often due to high recall and poor precision on English and Pidgin.
Khoury College of Computer Sciences
Northeastern University
Boston, MA 02115

Khoury College of Computer Sciences
Northeastern University
Boston, MA 02115
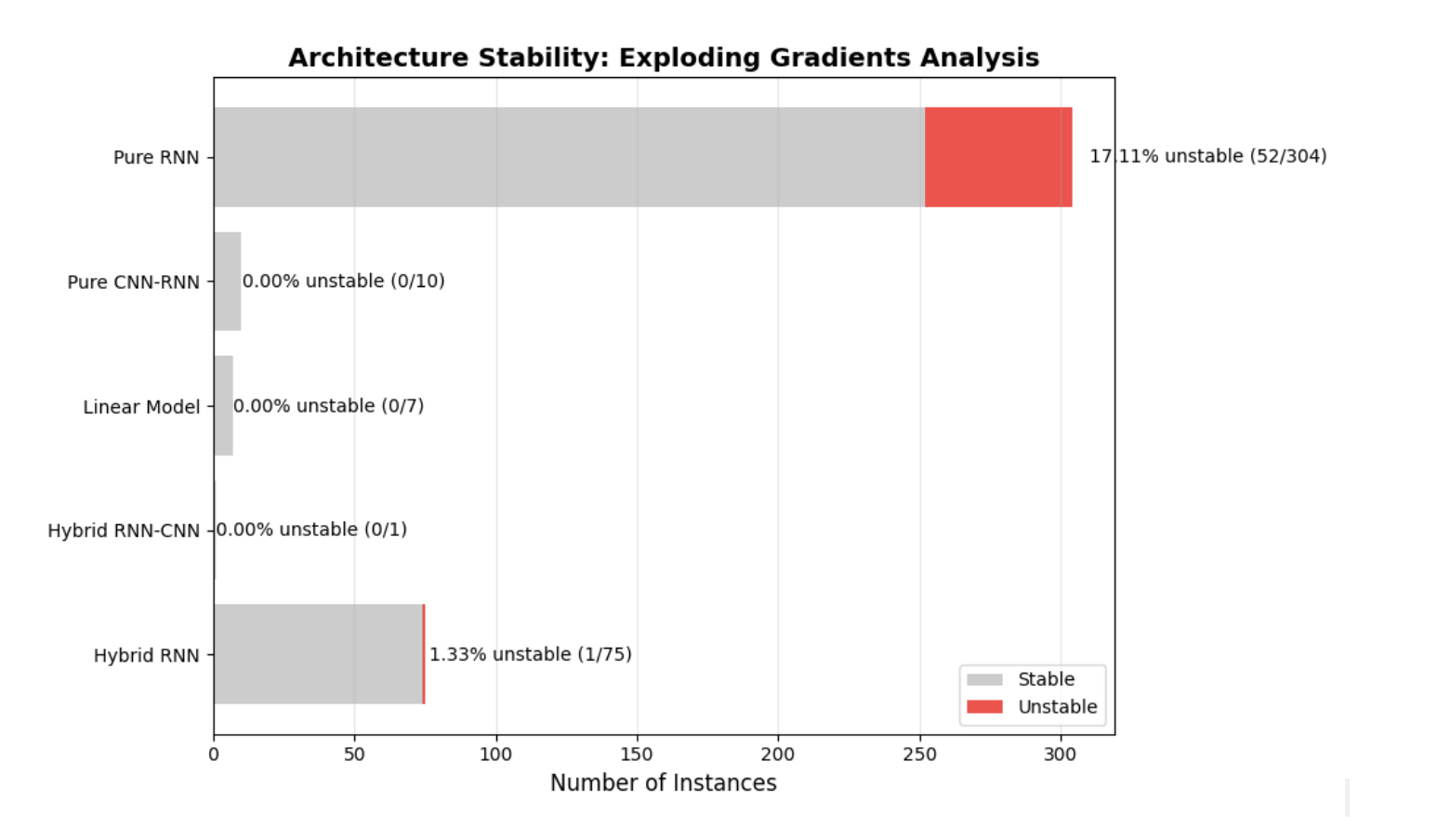
Among the unstable architectures, 52 were Pure RNNs (98.11% of unstable networks; 17.11% of all Pure RNNs) and 1 Hybrid RNN (1.89% of unstable networks; 1.33% of all Hybrid RNNs). The most frequently occurring layers in these unstable networks are summarized in Figure H. Results indicate that LSTM and GRU layers account for the majority of gradient-exploding networks, with over 90% of their instances leading to exploding gradients. Bidirectional layers, which are wrappers for LSTM and GRU layers, also caused exploding gradients in all three instances in which they appeared in the population. SimpleRNN layers had the lowest proportional presence, with only 7.45% of instances contributing to exploding gradients, although they represented a quarter of all unstable networks.
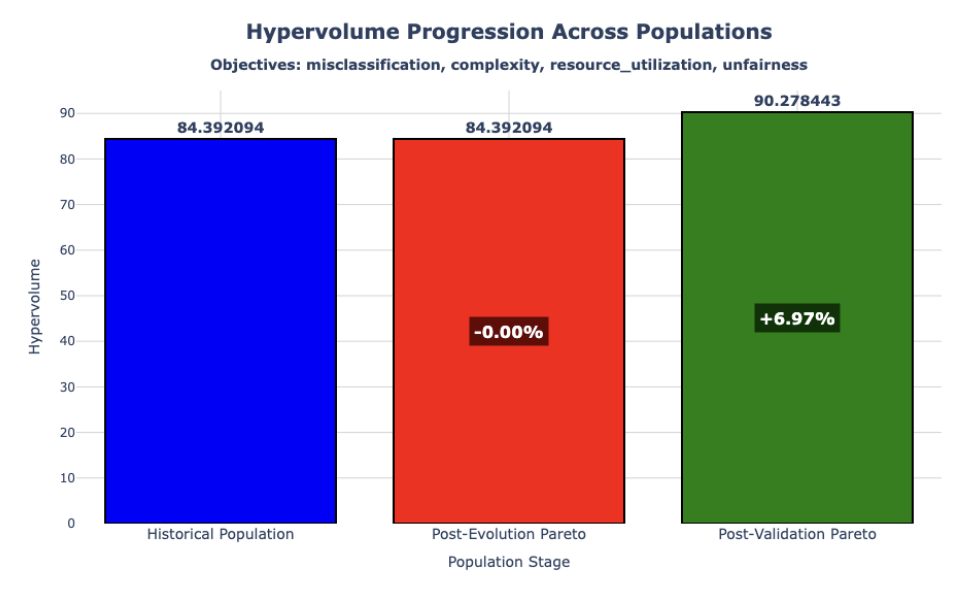
The hypervolume indicator quantifies the size of the objective space dominated by a set of solutions, reflecting both convergence to the Pareto front and diversity across objectives. This metric is widely used to evaluate evolutionary multi-objective optimization algorithms, particularly for problems with fewer than five objectives, as computational cost increases rapidly with the number of objectives (Guerreiro et al., 2020). Hypervolume values for each population subset along the path of convergence to the true Pareto front were calculated using the Python library PyMoo. The historical population exhibited a hypervolume of 84.39, serving as the baseline (0% improvement). The post-evolution Pareto front maintained a similar hypervolume (84.39), indicating negligible change in the dominated objective space. By contrast, the post-validation Pareto front showed a substantial increase in hypervolume to 90.28: a 6.98% improvement.
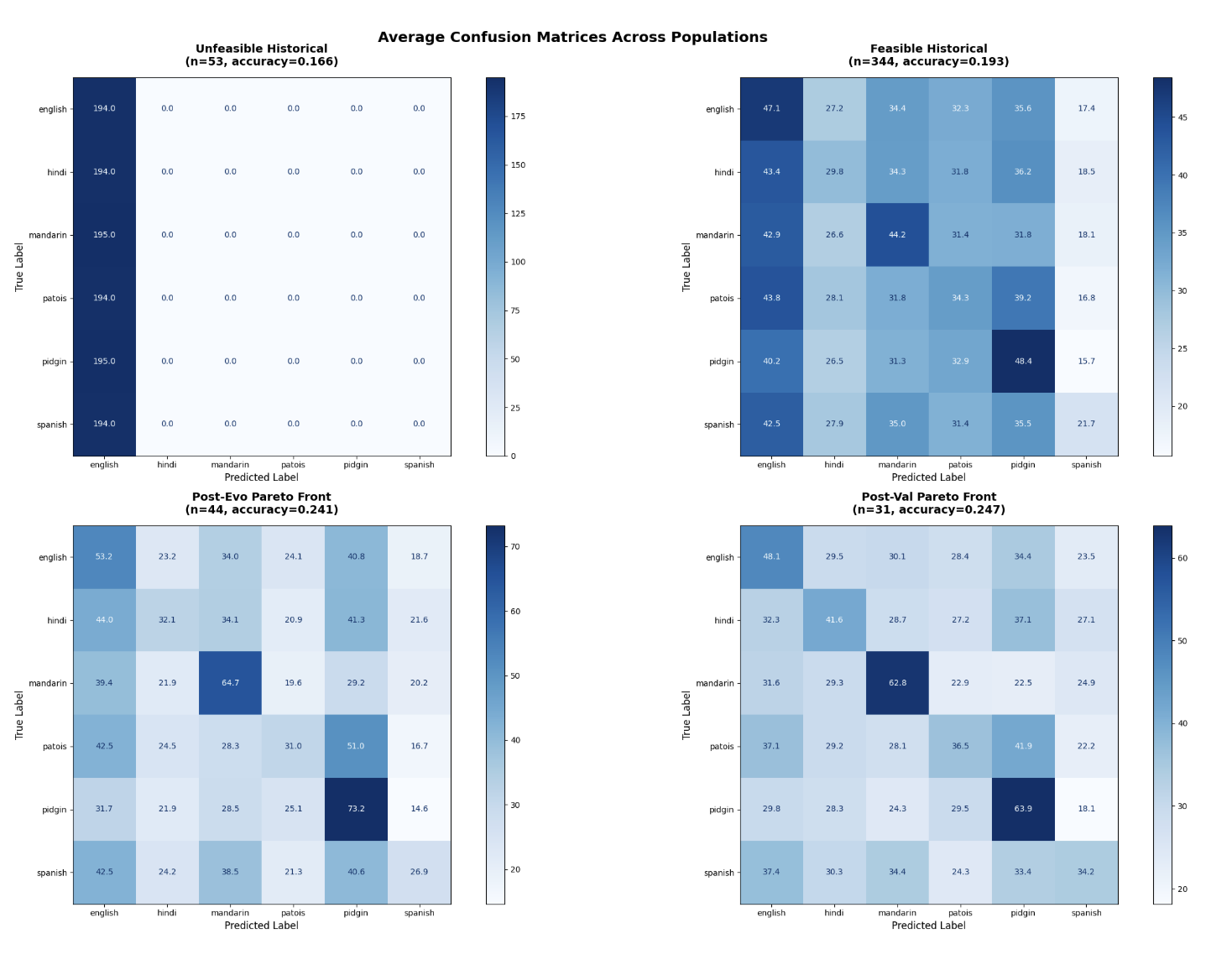
In the infeasible historical population, English clearly dominated among models with exploding gradients. Once these constraint-violating models are removed, English still dominates, but Mandarin and Pidgin begin to show increasing true positive counts. On average, Pidgin achieves a higher true positive count (48.4) than English (47.1), while Mandarin reaches 44.2. Most English false positive predictions for each language remain above 40, indicating that about 25% of the time a language will be misclassified as English. As the population transitions to the post-evolution Pareto front, Pidgin emerges with the highest average true positive count, though it also exhibits the highest false positive count. English predictions decrease in frequency, a trend that continues in the post-validation Pareto front. Mandarin and Pidgin maintain the strongest true positive counts on average in the post-evolution subset, while the overall true positive counts slightly decline in the post-validation Pareto front. Meanwhile, Spanish and Hindi exhibit steady increases in their average true positive counts as the population converges toward the final Pareto front.
In the feasible historical population, English is most frequently misclassified as Pidgin, while all other languages are predominantly misclassified as English. Only Mandarin and Hindi have higher counts of correct predictions than false negatives misclassified as English, indicating that their true positive counts exceed their misclassification to English. All other languages show lower true positive counts than their false-negative predictions as English. In the post-evolution Pareto front, English and Patois are most misclassified as Pidgin, whereas Hindi, Pidgin, Spanish, and Mandarin are most misclassified as English. In the post-validation Pareto front, the misclassification pattern remains the same, except Hindi is now mostly confused for Pidgin instead of English, and Pidgin is misclassified the most not only as English but also as Patois.
In the feasible historical population, when the model predicts English incorrectly, the true language is most often Patois; in the post-evolution Pareto front, it is Hindi; and in the post-validation Pareto front, it is Spanish. When Hindi is falsely predicted, the true language is most often Patois in the feasible historical population and post-evolution Pareto front, and Spanish in the post-validation Pareto front. For Mandarin, false positives most frequently correspond to Spanish across all three population subsets. When Patois is falsely predicted, the actual language is predominantly Pidgin, and conversely, when Pidgin is falsely predicted, the actual language is most often Patois in all three subsets. Finally, for Spanish, false positives primarily occur when the true language is Hindi across all populations.